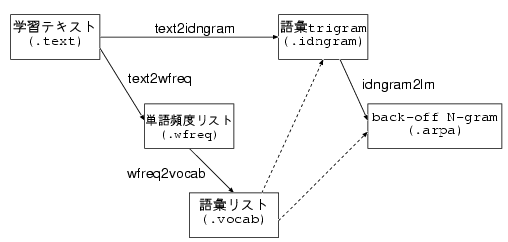
単語N-gram作成手順
|
伊藤 彰則 山形大学 工学部 aito@eie.yz.yamagata-u.ac.jp |
我輩 は 猫 であ る 。 名前 は まだ な い 。 |
我輩+名詞 は+助詞 猫+名詞 であ+助動詞 る+語尾 。+記号 名前+名詞 は+助詞 まだ+副詞 な+形容詞 い+語尾 。+記号 |
文脈情報(コンテキストキュー)として, <s>(文頭),</s>(文末),<p>(パラグラフ) のような特殊記号を使うこともできる.これらの記号は, 自分で定義することが可能である(後述の .ccsファイル参照).
アドバンスト 1 衛星通信 17 相談所 9 現象 390 現職 97 現場 569 ... |
、 。 , . ・ : ? ! 〃 々 〇 |
text2wfreq learn.text learn.wfreq
のようにする.入出力ファイルが拡張子 .gz をもっていれば、
自動的に圧縮ファイルとみなして gzip により伸長・圧縮する。
入出力ファイルを引数に指定しなければ、.textファイルを標準入力、
.wfreqファイルを 標準出力に割りあてる(CMU-Cambridge SLM toolkit互換)ので、
text2wfreq < learn.text > learn.wfreq
のように使うことができる。
wfreq2vocab -top 5000 learn.wfreq learn.vocab5k
のようにする.結果のファイルの拡張子( .vocab5k)は,5000語彙の
リストという意味だが,特にこういう形式でなければならないということは
なく,適当に付けてもよい.
上位n個という指定ではなく,例えば30回以上出現した単語を語彙とする
場合には,
wfreq2vocab -gt 29 learn.wfreq learn.vocab5k
とする(gt は grater than の略).
入出力ファイルを引数に指定しなければ、.wfreqファイルを標準入力、 .vocabファイルを 標準出力に割りあてる(CMU-Cambridge SLM toolkit互換)ので、
wfreq2vocab -top 5000 < learn.wfreq > learn.vocab5k
のように使うことができる。
text2idngram -vocab learn.vocab5k learn.text learn.id3gram
のようにする.text2wfreqの場合と同じように,圧縮ファイルを扱う
こともできる.
idngram2lm -idngram learn.id3gram -vocab learn.vocab5k -arpa learn.arpa
これで,back-off 言語モデルのファイル learn.arpa.gz が生成される.
idngram2lmは,圧縮ファイルにも対応しており,
idngram2lm -idngram learn.id3gram.gz -vocab learn.vocab5k.gz -arpa learn.arpa.gz
のように,圧縮したファイルを指定することもできる.
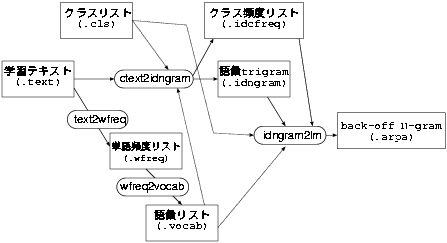
text2wfreq learn.text learn.wfreq
のようにする.入出力ファイルが拡張子 .gz をもっていれば、
自動的に圧縮ファイルとみなして gzip により伸長・圧縮する。
入出力ファイルを引数に指定しなければ、.textファイルを標準入力、
.wfreqファイルを 標準出力に割りあてる(CMU-Cambridge SLM toolkit互換)ので、
text2wfreq < learn.text > learn.wfreq
のように使うことができる。
wfreq2vocab -top 5000 learn.wfreq learn.vocab5k
のようにする.結果のファイルの拡張子( .vocab5k)は,5000語彙の
リストという意味だが,特にこういう形式でなければならないということは
なく,適当に付けてもよい.
上位n個という指定ではなく,例えば30回以上出現した単語を語彙とする
場合には,
wfreq2vocab -gt 29 learn.wfreq learn.vocab5k
とする(gt は grater than の略).
入出力ファイルを引数に指定しなければ、.wfreqファイルを標準入力、 .vocabファイルを 標準出力に割りあてる(CMU-Cambridge SLM toolkit互換)ので、
wfreq2vocab -top 5000 < learn.wfreq > learn.vocab5k
のように使うことができる.
text2idngram -vocab learn.vocab5k -class learn.cls -idwfreq learn.idwfreq learn.text learn.cid3gram
のようにする.生成されるのは,クラス列に対するidngramと,各単語の
出現頻度ファイルである idwfreq である.
idngram2lm -idngram learn.id3gram -vocab learn.vocab5k -class learn.cls -idwfreq learn.idwfreq -arpa learn.arpa.gz
これで,back-off 言語モデルのファイル learn.arpa.gz が生成される.
% evallm -arpa learn.arpa -context learn.ccs Reading LM file learn.arpa 1-grams:..2-grams:.....3-grams:......... evallm : perplexity -text test.text Number of word = 220248 13850 OOVs and 10000 context cues are excluded from PP calculation. Total log prob = -1.15381e+06 Entropy = 7.55782 (bit) Perplexity = 188.421 Number of 3-grams hit = 74209 (33.69%) Number of 2-grams hit = 82637 (37.52%) Number of 1-grams hit = 63402 (28.79%) evallm : quit evallm : done.基本的な使い方としては,
evallm -arpa 言語モデル -context コンテキストキュー
でevallmを起動し,evallm:のプロンプトで
perplexity -text 評価テキスト
を入力する.この場合の評価テキストは,学習テキストと同じく,
単語間を空白で区切ったテキストファイルでなければならない.
評価テキストはコマンドラインで指定することもできる。この場合、
evallm -arpa 言語モデル -context コンテキストキュー -text 評価テキスト
のように指定する。
言語モデルの指定の書式は、次のようである。
ファイル名[;長さ][*重み][,ファイル名[;長さ]*重み...]